
Sql Server數據庫優化的一些高級方法2

1,查詢沒有使用參數化的語句,參數化很重要也很簡單
1)腳本每次進入數據庫執行,只編譯一次。能提高性能
2)眾所周知的簡單
SELECT TOP 10
MAX(Text) '示例語句' ,
SUM(CAST(size_in_bytes AS BIGINT)) / 1024. / 1024. AS '占用服務器內存Size(MB)' ,
COUNT(1) '緩存計劃數'
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
--cross apply sys.dm_exec_text_query_plan(plan_handle,default,default)
WHERE Objtype IN ( 'Adhoc', 'Prepared' )
AND text NOT LIKE '(@%'
AND text NOT LIKE '%sys%'
GROUP BY LEFT(TEXT, 20)
HAVING COUNT(1) > 10
ORDER BY '緩存計劃數' DESC
2,查看數據庫腳本的cpu和磁盤統計
SET statistics time on
SET statistics io on
只在當前查詢頁起作用,關掉當前查詢tab即關掉了
3,顯示估計執行計劃,根據建議可直接建立缺省索引
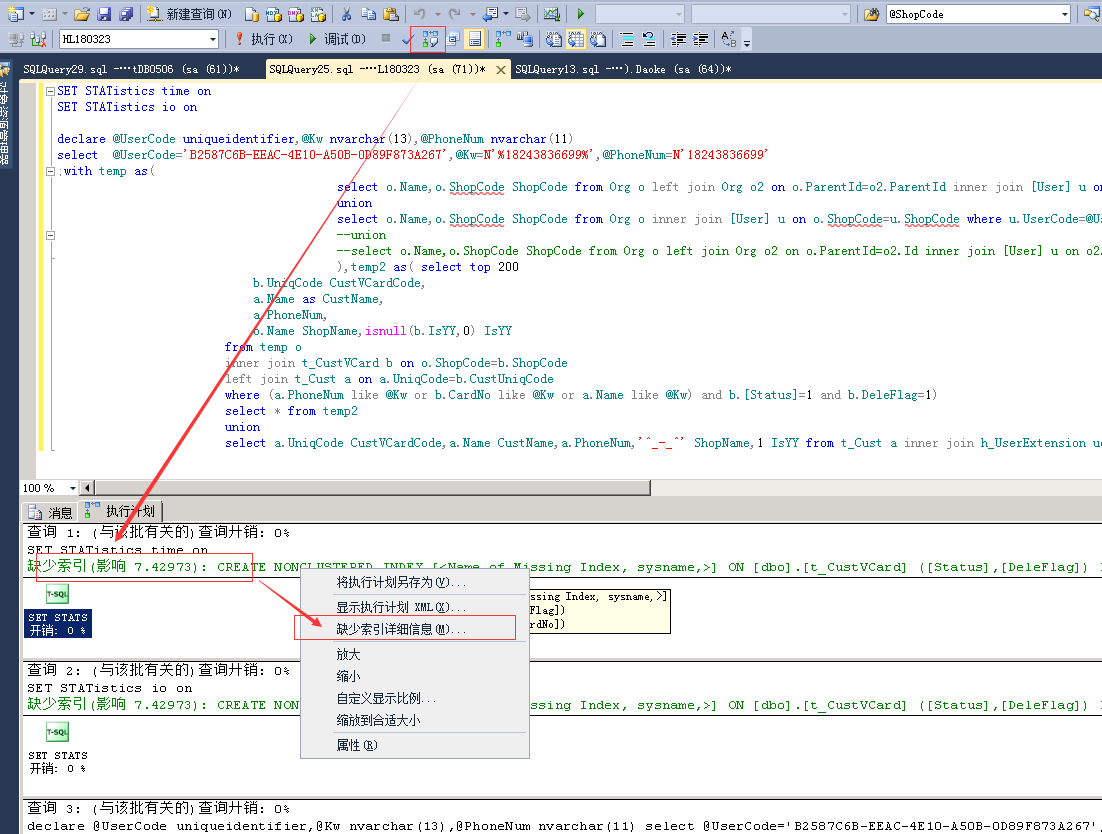
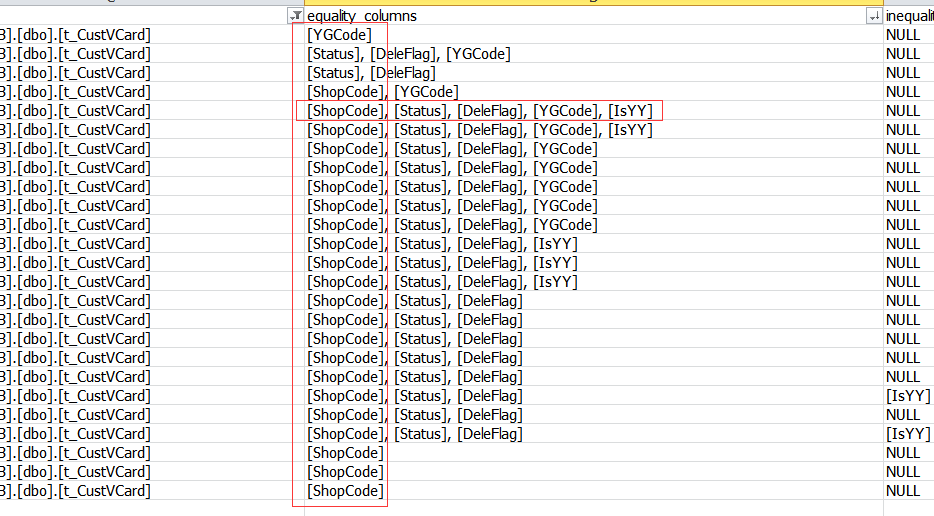
4,根據前一篇文章(摸這里)可查詢到頻繁查詢而需要建立的索引。好的索引可以極大提高性能。
建立索引的原則:
1)能極大減少數據量的字段放在前面;
2)第一個字段的不同決定要建立幾個索引(下圖一般需要三個)
3)索引需要的字段一般以最多的為準,被用到最多的放在前面
5,附件中為產生需要重建的索引的腳本的存儲過程的生成腳本(附件摸這里)
其中sql server 2012商務智能版本不支持腳本中的WITH(ONLINE=ON),可根據具體情況將其去掉。
定期執行該存儲過程,清理重新生成索引,清理索引碎片。
6,創建索引的最簡單語句
Create index IX_t_CustVCard_YGCode
on [t_CustVCard]([YGCode])
include([CustUniqCode])
7,SqlServer的一些基本輔助函數:
sp_helpindex 標明 -------------------查詢這個表有多少個索引
8,備份數據庫策略:(附件摸這里)
舉個例子:一周做一個完整備份,一個小時做一次日志備份,還原的時候依次還原即可。腳本見附件。